Pekiştirmeli Öğrenmede Modern Algoritmalar: A2C, PPO ve TD3’ü LunarLander’da Test Ediyoruz

Pekiştirmeli öğrenme (RL) algoritmaları son yıllarda inanılmaz bir gelişme gösterdi. Bu yazıda, üç modern RL algoritmasını - A2C, PPO ve TD3 - hem teorik hem de pratik olarak inceleyeceğiz. Hepsini OpenAI Gym’in klasik LunarLander ortamında test ederek gerçek performanslarını karşılaştıracağız.
Blogun içeriği :
- Neden Bu Üç Algoritma?
- 1. A2C (Advantage Actor-Critic)
- 2. PPO (Proximal Policy Optimization)
- 3. TD3 (Twin Delayed Deep Deterministic Policy Gradient)
- Performans Karşılaştırması
- Pratik İpuçları
- Eğitilmiş Modelleri Test Etme
- En Optimal PPO Modelinin Performansı
- Sonuç
Neden Bu Üç Algoritma?
- A2C: Actor-Critic ailesinin modern ve verimli üyesi
- PPO: OpenAI’ın go-to algoritması, kararlılığıyla ünlü
- TD3: Sürekli kontrol problemleri için geliştirilmiş güçlü bir algoritma
1. A2C (Advantage Actor-Critic)
Teori
A2C, hem politika (actor) hem de değer fonksiyonu (critic) öğrenen bir algoritmadır. Temel matematiksel formülasyonu:
Actor Kaybı: \(L_{actor} = -\frac{1}{N}\sum_{i=1}^{N} \log \pi_\theta(a_i|s_i) \cdot A_i\)
Critic Kaybı: \(L_{critic} = \frac{1}{N}\sum_{i=1}^{N} (R_i - V_\phi(s_i))^2\)
Aşağıda, PPO algoritmasında küçük politika güncellemelerinin büyük adımlara kıyasla neden daha etkili olabileceğini gösteren bir görsel yer alıyor.

Implementasyon
from stable_baselines3 import A2C
from stable_baselines3.common.env_util import make_vec_env, SubprocVecEnv
env = make_vec_env('LunarLander-v3', n_envs=8, vec_env_cls=SubprocVecEnv)
model = A2C(
"MlpPolicy",
env,
n_steps=5,
gamma=0.99,
learning_rate=linear_schedule(0.00083),
ent_coef=0.01, # Entropi katsayısı - keşfi teşvik eder
verbose=0,
)
# 400K adım eğitim
model.learn(total_timesteps=4e5)
Sonuçlar
- Eğitim öncesi: -814.50 ± 645.16
- Eğitim sonrası: 52.72 ± 134.52
2. PPO (Proximal Policy Optimization)
Teori
PPO’nun sırrı, politika güncellemelerini kontrol altında tutması. Kırpılmış amaç fonksiyonu sayesinde büyük politika değişikliklerini engeller:
\[L^{CLIP}(\theta) = \mathbb{E}_t[\min(r_t(\theta)A_t, \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon)A_t)]\]Implementasyon
from stable_baselines3 import PPO
env = make_vec_env('LunarLander-v3', n_envs=8)
model = PPO(
"MlpPolicy",
env,
n_steps=4,
batch_size=64,
gamma=0.999,
learning_rate=3e-4,
ent_coef=0.01,
gae_lambda=0.98, # GAE için lambda
verbose=0,
)
model.learn(4e5, progress_bar=True)
Sonuçlar
- Eğitim öncesi: -325.16 ± 124.20
- Eğitim sonrası: 59.04 ± 130.47
3. TD3 (Twin Delayed Deep Deterministic Policy Gradient)
Teori
TD3, sürekli aksiyon uzayları için tasarlanmış ve üç ana yenilik içeriyor:
- İkiz Q-Fonksiyonları: Aşırı tahmin problemini çözer
- Geciktirilmiş Güncellemeler: Actor’ü daha az günceller
- Hedef Yumuşatma: Hedef eylemlere gürültü ekler
Aşağıda TD3 mimarisin gösteren bir görsel yer almaktadır.

Implementasyon
LunarLander’ın sürekli versiyonunu kullanıyoruz:
from stable_baselines3 import TD3
from stable_baselines3.common.noise import NormalActionNoise
env = make_vec_env('LunarLanderContinuous-v3', n_envs=8)
# Aksiyon gürültüsü ekle
n_actions = env.action_space.shape[-1]
action_noise = NormalActionNoise(
mean=np.zeros(n_actions),
sigma=0.1 * np.ones(n_actions)
)
model = TD3(
"MlpPolicy",
env,
gamma=0.98,
buffer_size=200_000,
learning_starts=10_000, # Replay buffer dolana kadar bekle
action_noise=action_noise,
)
model.learn(4e5, progress_bar=True)
Sonuçlar
- Eğitim öncesi: -188.16 ± 89.84
- Eğitim sonrası: 15.18 ± 85.51
Performans Karşılaştırması
| Algoritma | Ortam | Başlangıç Skoru | Final Skoru | İyileşme |
|---|---|---|---|---|
| A2C | LunarLander-v3 | -814.50 | 52.72 | ✅ Büyük iyileşme |
| PPO | LunarLander-v3 | -325.16 | 59.04 | ✅ En iyi sonuç |
| TD3 | LunarLanderContinuous-v3 | -188.16 | 15.18 | ✅ Sürekli kontrolde başarılı |
Pratik İpuçları
1. Ortam Seçimi
- Ayrık aksiyonlar: A2C veya PPO kullanın
- Sürekli aksiyonlar: TD3 tercih edin
2. Hiperparametre Ayarları
- Optimal parametreler için RL Zoo3 kullanın
- Learning rate schedule kullanmayı unutmayın
3. Paralel Ortamlar
# Daha hızlı eğitim için birden fazla ortam kullanın
n_envs=8 # CPU çekirdek sayınıza göre ayarlayın
Eğitilmiş Modelleri Test Etme
# Model kaydetme
model.save("ppo_lunarlander")
# Yükleme ve test
model = PPO.load("ppo_lunarlander")
obs = eval_env.reset()
for _ in range(1000):
action, _ = model.predict(obs, deterministic=True)
obs, reward, done, info = eval_env.step(action)
eval_env.render()
En Optimal PPO Modelinin Performansı
PPO modelini alıp yeterince uzun süre eğitirseniz (mean_reward = 200 olana kadar) aşağıdaki gibi bir davranışı olacaktır :
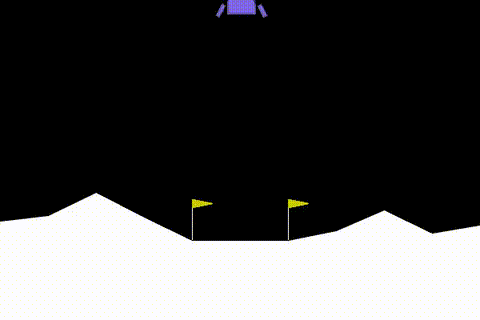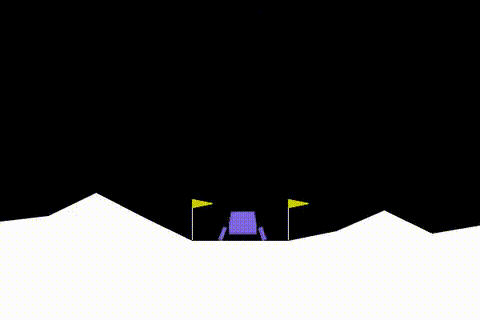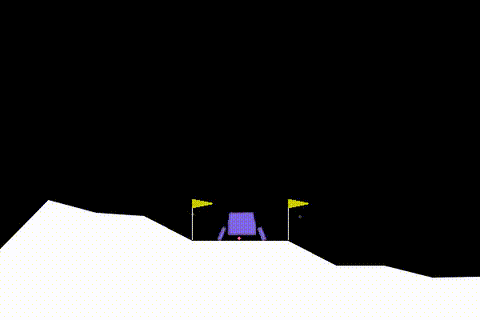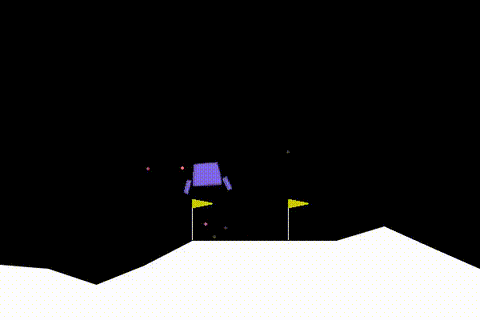
Sonuç
Bu üç algoritma modern RL’nin temellerini oluşturuyor:
- A2C: Basit ve etkili, başlangıç için ideal
- PPO: Kararlı ve güvenilir, çoğu problem için go-to seçim
- TD3: Sürekli kontrol problemlerinde üstün performans
Kodların tamamına GitHub repo linki üzerinden ulaşabilirsiniz.